Tokenizer(公式のトークン数確認ツール)を使ってどんな文字だと何トークンに何かを検証。
※「GPT-3」の設定で検証。将来、「GPT-4」の設定など他のものだとルールが変わる可能性が有ります。
※このルールと外れる様なパターンを見つけた方はコメント欄に書いて貰えると嬉しいです。
ツールの解説
このツールでは文字の背景色が同じ色の範囲が1トークンを表しています。 Tokens にトークン数、 Characters に文字数が表示されます。
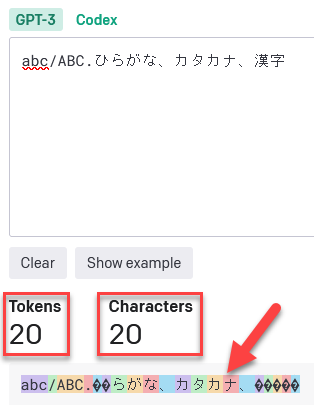
英語
「英語」は1単語、基本1トークン。
「red」「three」で検証。
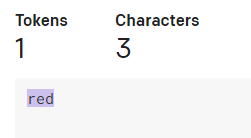
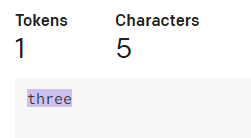
文字数が多いとトークン数が増える事が有る。おおよそ4文字で1トークンくらい。
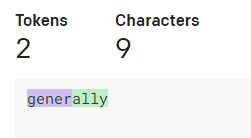
5文字以上だと常に2トークンというわけでは無く、文字数が多くても1トークンな単語も有る。
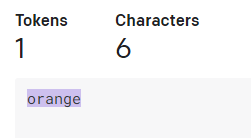
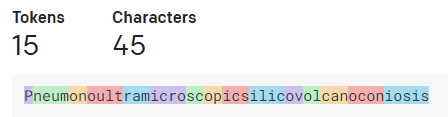
一般的な英語辞書に載っている中で一番長い単語と言われている「Pneumonoultramicroscopicsilicovolcanoconiosis」は45文字で15トークン。
日本語
ひらがな
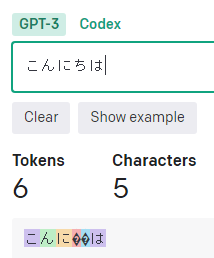
「ひらがな」は1文字、1~2トークン。
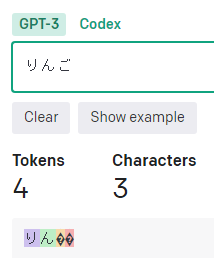
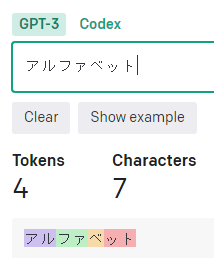
(全角)カタカナ
「カタカナ」は1文字、基本1トークン。
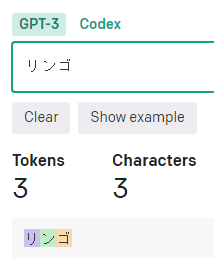
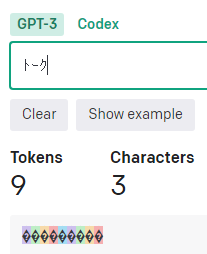
長文を入れてみると文字数よりトークン数が少ないという結果が発生。

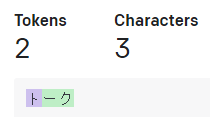
よく見ると「ーク」の所が1トークン扱いになっています。

長音記号とその後の文字とセットでで1トークンという法則が有りそうです。
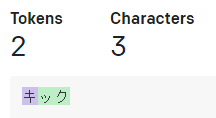
「ッ」などの小さい文字(捨て仮名)もその後の文字とセットで1トークン。
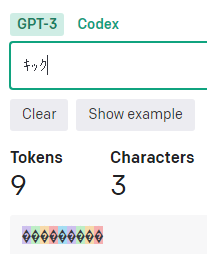
半角カタカナ
「半角カタカナ」は1文字、3トークン。
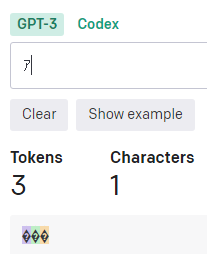
「゙」(濁点)や「゚」(半濁点)もそれぞれ3トークン。 ※UTF-8でそれぞれ3バイト。
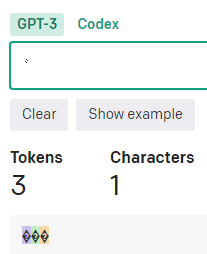
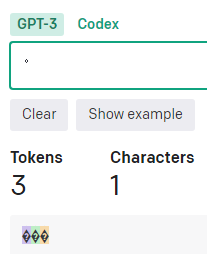
全角カタカナの時と違い、「ーク」や「ック」の場合に半分のトークン数になるという事は無い。
という事で、特別な理由が無い限りは全角カタカナを使った方が良いでしょう。
漢字
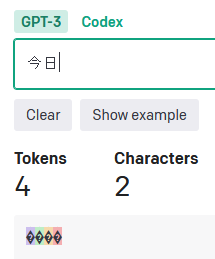
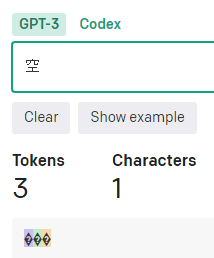
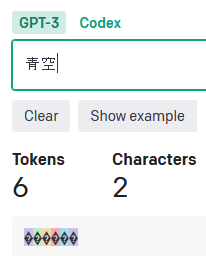
「漢字」は1文字、基本2~3トークン(レア漢字だとそれ以上の場合も)。
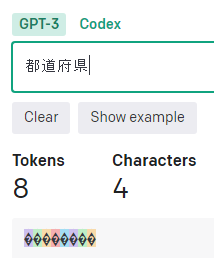
「今日」や「都道府県」は「文字数x2=トークン数」ですが、それ以外は「文字数x3=トークン数」になっています。
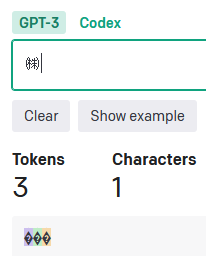
「𠮷」(つちよし)や「𩸽」(ほっけ)だと4トークン。2文字と認識されているのも気になります。
※UTF-8で4バイト。
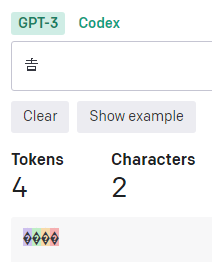
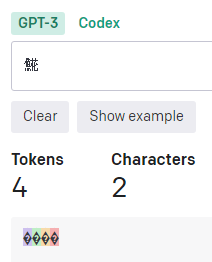
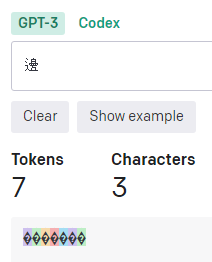
渡辺の「辺」の異体字である「邊󠄄」だと7トークンにもなる。3文字と認識されているのも気になります。
※ちなみにUTF-8で処理しようとするとIVSなので7バイト。
絵文字
「絵文字」は1文字、基本2トークン。
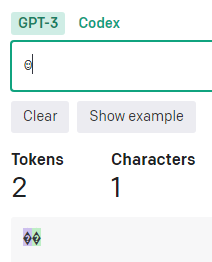
旧絵文字の「☺」は2トークン。
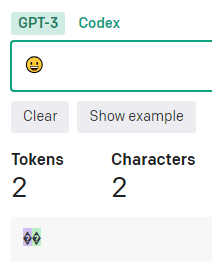
カラー絵文字の「😀」も2トークン。なぜか2文字と認識。
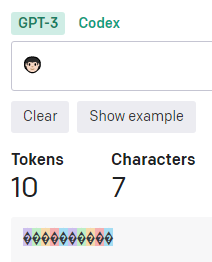
サロゲートペアを使っている「🧑🏻」(明るい肌色の顔)※参考ページの絵文字だと10トークンになる事も。コードポイントは1F9D1 1F3FB。UTF-8で8バイト。
「👨👩👦」(家族: 男性、女性、男の子)※参考ページの場合も10トークン。コードポイントは1F468 200D 1F469 200D 1F466。UTF-8で18バイト。
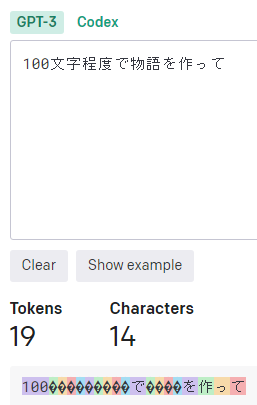
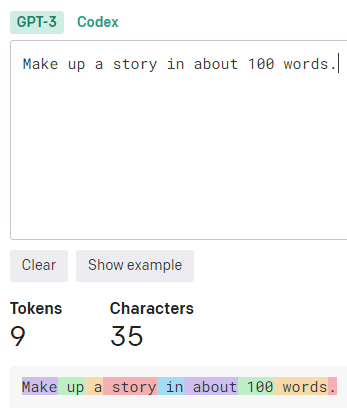
日本語の文章と英語の文章の比較
同じ内容でも日本語の場合は19トークン、英語の場合は9トークンになりました。英文の最後のピリオドは省略しても問題無い事が多いのでそこまで攻めると8トークンまで減らす事も可能ですね。中々、大きな違いです。
ChatGPT で長文の文章を使いたい時や ChatGPT API を使う時のコストを抑える事を考えると英語で問題無い場面では英語を使う方が良さそうです。
公式の情報
Tokenizerのページの注記。
経験則として、一般的な英語のテキストでは、1トークンは~4文字のテキストに相当します。これはおよそ1単語の3/4に相当します(つまり100トークン~=75単語)。
ヘルプページ「トークンとは何ですか?またその数え方は?」。
1 トークン ~= 英語の 4 文字 1 トークン ~= ¾ ワード 100 トークン ~= 75 ワード また 1-2 文 ~= 30 トークン 1 段落 ~= 100 トークン 1,500 ワード ~= 2048 トークン ウェイン・グレツキーの名言 "You miss 100% of the shots you don't take" には 11 個のトークンが含まれています。 OpenAI の憲章には 476 個のトークンが含まれています。 米国独立宣言の謄本には1,695 個のトークンが含まれています